
드디어 어려워서 계속 미뤄왔던 남은 마지막 챕터를 정리하네요. 이 포스팅은 아래 책을 정리하며 공부한 내용입니다. 좋은 책을 출판해주신 저자님께 감사드립니다 😊
http://www.yes24.com/Product/Goods/44376723
DevOps와 SE를 위한 리눅스 커널 이야기 - 예스24
커널은 오랜 세월 기능이 추가되고 개선되어 오면서 완벽하게 이해하기 힘들 정도로 방대해졌다. 하지만 변하지 않는 기본 기능들이 있다. 이런 근간이 되는 기능에 대한 이해를 바탕으로 시스
www.yes24.com
목차
- I/O 스케줄러의 필요성과 역할
- I/O 스케줄러와 파라미터 튜닝
1) Non-Multiqueue 스케줄러
> CFQ
> Deadline
> Noop
- Miltiqueue의 배경
3) Multiqueue 스케줄러
> MQ-deadline
> None
> BFQ
> Kyber
시스템에서 I/O 작업이 발생하면 가상 파일 시스템과 로컬 파일 시스템을 거쳐 I/O 스케줄러에 병합과 정렬을 통해 queueing 되고 순차적으로 블록 디바이스에 전달됩니다. 여기서 서버의 워크로드와 I/O 스케줄러의 알고리즘에 따라 성능이 달라집니다.
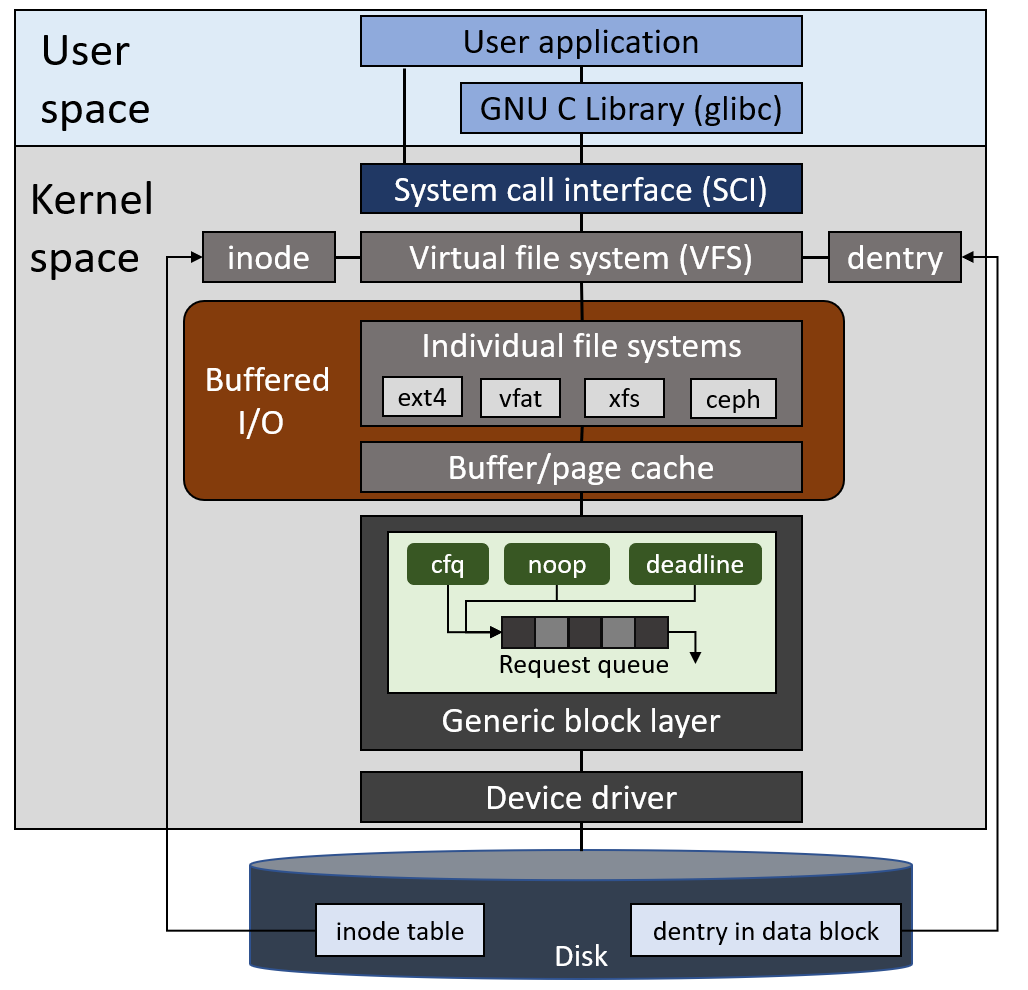
- I/O 스케줄러의 필요성과 역할
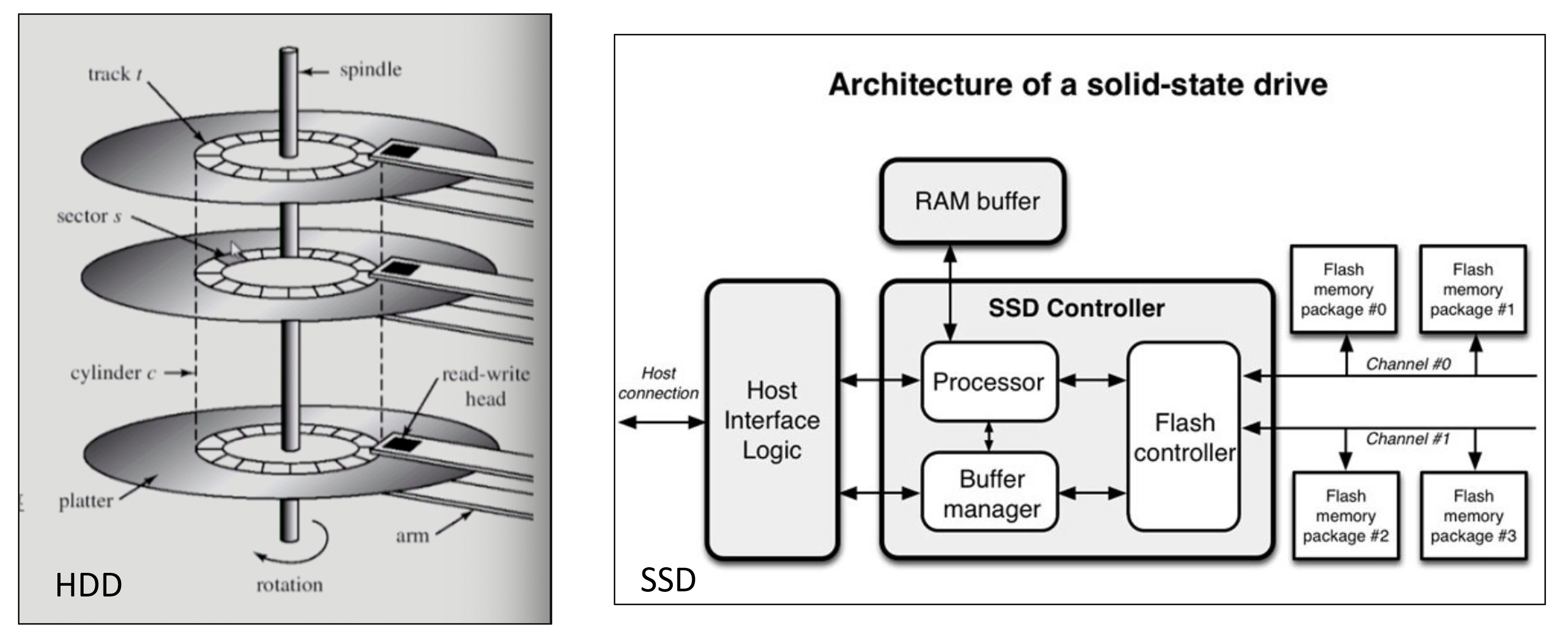
플래시 메모리를 기반으로 하는 SSD와 달리 HDD는 헤드의 물리적인 이동에 따른 지연이 발생하며, 한 번 디스크 섹터를 이동할 때 I/O 요청을 최대한 처리해야 성능을 극대화할 수 있습니다.
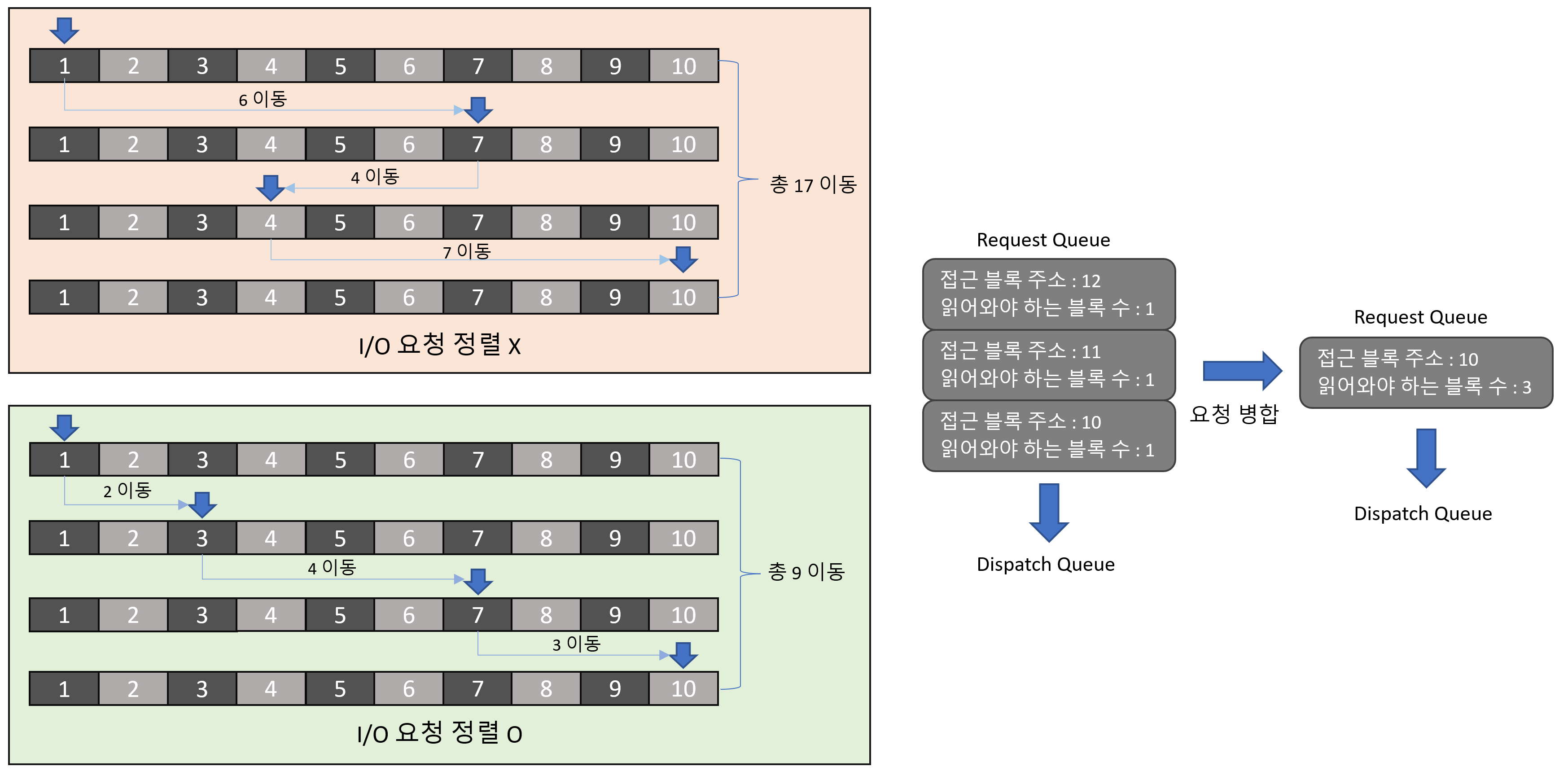
아래 예시처럼 3개의 I/O 요청을 하나로 병합해서 디스크 헤드의 동선을 최적화할 수 있습니다.
I/O 요청을 병합하고 정렬하지 않은 경우 I/O 요청마다 헤드가 각각 이동하여 데이터를 처리해야합니다. 반면, 요청을 병합하고 정렬한 경우 더 적은 헤드의 이동으로 모든 데이터를 처리할 수 있습니다.
* 디스크 타입 확인 방법
root@master-1:~ # lsblk -d -o name,rota
NAME ROTA
sda 0
sdb 0
sdc 1
# ROTA 1 → HHD
# 0 → SSD
- I/O 스케줄러 종류와 설정 방법
스케줄러의 방식에 따라 non-multiqueue와 multiqueue 방식 2가지가 있습니다.
non-multiqueue 스케줄러는 단일 FIFO 큐로 구현되어 있는 반면 multiqueue 스케줄러는 I/O 요청을 저장 장치의 여러 queue에 동시에 매핑하여 병렬 처리를 합니다.
아래 명령어 처럼 디스크 별로 스케줄러를 변경할 수 있습니다.
# Non-multiqueue scheduler (kernel 4.x 이전)
root@compute-1-1:~# cat /sys/block/sda/queue/scheduler
noop deadline [cfq]
root@compute-1-1:~# echo deadline > /sys/block/sda/queue/scheduler
root@compute-1-1:~# cat /sys/block/sda/queue/scheduler
noop [deadline] cfq
# Multiqueue scheduler (kernel 5.x 이후)
master-2:# cat /sys/block/sda/queue/scheduler
[mq-deadline] kyber bfq none
1. cfq I/O 스케줄러 (Completely Fair Queueing) [ non-multiqueue ]
cfq 스케줄러는 프로세스마다 각각의 queue를 가지며, 디스크의 대역폭에 따라 일정한 slice로 나누어 각 프로세스의 I/O 요청을 공정하게 처리합니다.
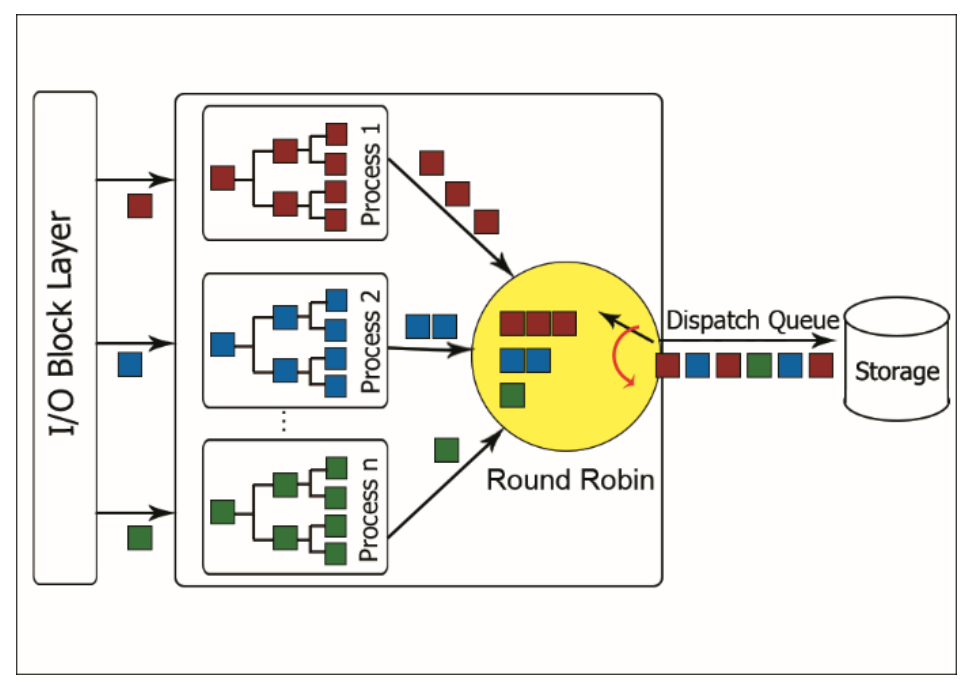
좀 더 세부적으로 보겠습니다.
프로세스의 I/O 요청은 Block layer를 거쳐서 cfq로 인입되면 우선순위에 따라 RT(Real Time), BE(Best Effort), IDLE로 나눠집니다. RT는 BE와 IDLE보다 항상 먼저 처리되므로 RT에 해당하는 I/O가 많으면 후순위의 요청에서 기아 상태가 발생할 수 있습니다. RT와 BE는 각 클래스에서 0~7까지의 하위 우선순위로 나누어집니다. IDLE 클래스는 다른 우선순위 클래스에 대기중인 I/O 요청이 없을 때 처리됩니다.
우선순위 클래스가 분류된 이후 service tree라고 불리는 워크로드별 그룹(SYNC, SYNC_NOIDLE, ASYNC)로 다시 나눠집니다. 이 후 I/O 작업을 요청한 프로세스에 따라 요청이 인입될 cfq queue가 결정되고, 각각 동등한 time slice를 할당하여 round-robin으로 처리됩니다.
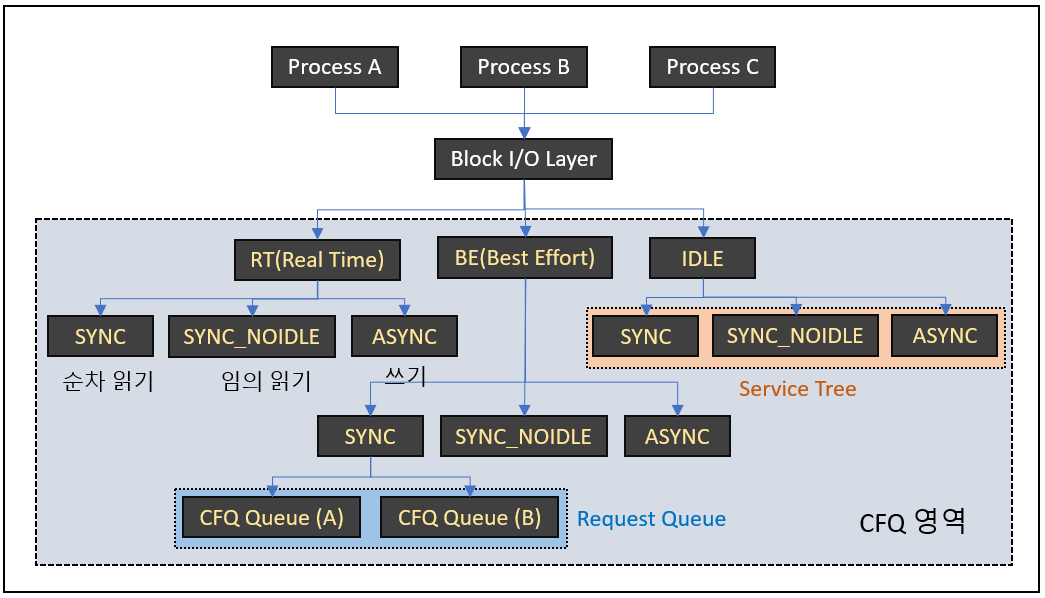
- SYNC : 순차적 동기화 I/O 작업으로 순차 읽기(Sequential read) 또는 Direct write을 의미합니다. 순차 작업이므로 이후에 발생할 I/O 요청이 이전의 디스크 섹터와 인접할 가능성이 큽니다. 즉, 큐의 작업을 처리한 후 일정 시간동안 대기하여 현재 헤드의 위치에서 인접한 섹터의 I/O 요청을 기다렸다가 처리합니다. 예를 들어 어플리케이션이 config 파일을 읽는다면, 전체 파일을 다 읽어야 정상적으로 실행될 수 있습니다. 그래서 읽기 작업이 완료될 때 까지 어플리케이션을 블록하는 동기 작업으로 수행됩니다.
- SYNC_NOIDLE : 임의적 동기화 I/O작업으로 임의 읽기(Randome read)를 의미합니다. 임의 작업은 다음 I/O 요청의 디스크 섹터를 예측할 수 없기 때문에 대기 시간없이 바로 헤드를 이동합니다.
- ASYNC : 비동기 I/O 작업으로 쓰기 작업(Buffered write)을 의미합니다. 각 프로세스에서 발생한 쓰기 작업은 여기에 모여서 한 번에 처리됩니다.
* 대부분의 요청은 BE에 해당하며 ionice 명령어로 우선 순위 설정을 변경할 수 있습니다.
* cfq 스케줄러의 파라미터
root@compute-1-1:~# ls /sys/block/sda/queue/iosched
back_seek_max group_idle slice_async slice_idle_us target_latency_us
back_seek_penalty group_idle_us slice_async_rq slice_sync
fifo_expire_async low_latency slice_async_us slice_sync_us
fifo_expire_sync quantum slice_idle target_latency
- back_seek_max : 디스크 헤드의 위치를 기준으로 backward seeking의 최대 거리(Kbytes)를 의미합니다. 현재 헤드보다 뒤쪽 섹터로 back_seek_max 만큼을 다음 요청으로 예상하여 처리합니다. 순차 쓰기가 잦은 경우 이 값을 줄여 헤드의 움직임을 최소화할 수 있지만, 그 만큼 다른 요청이 지연될 수 있습니다. (Default 16384 = 16KB)
- back_seek_penalty : backward seeking의 패널티 값입니다. 일반적으로 디스크 헤드가 이동할 때 1 → 2 → 3 → 4로 이동하는 것이 1 → 3 → 2 → 4로 이동하는 것 보다 효율적입니다. 그래서 backward seeking에 대해 패널티를 주는 것입니다. 현재 헤드 위치가 1,024KB인 상황에서 1,008KB과 1,040KB에 대한 요청이 동시에 발생한 경우 두 요청에 대한 distance는 16KB로 동일합니다. 여기서 backward seeking에 패널티(Default 2)를 적용하여 32KB가 되고 헤드는 forward seeking을 수행하게 됩니다.
- fifo_expire_async : CFQ의 FIFO 리스트에서 async(쓰기 작업) 요청의 만료 시간을 정의합니다. (Default 250ms)
- fifo_expire_sync : CFQ의 FIFO 리스트에서 sync(읽기 작업) 요청의 만료 시간을 정의합니다. (Default 125ms)
- group_idle : 일반적으로 동일 cgroup의 프로세스 큐로 이동할 때에는 대기시간 없이 다음 큐로 넘어갑니다. 그러나 다른 cgroup의 프로세스 큐로 이동할 때는 추가로 발생할 I/O요청을 대비하기 위해 group_idle의 값만큼 대기했다가 다른 프로세스 큐로 이동합니다. (Default 8ms)
- quantum : SYNC(순차 읽기) 요청을 dispatch queue로 넘겨주는 최대 버퍼값입니다. 요청이 해당 값을 초과해야 큐로 넘겨줍니다. 디스크가 여러 장인 시스템의 경우 I/O 병렬처리가 가능하므로, quantum 값을 늘려서 큐에서 한 번에 꺼낼 수 있는 요청의 개수 늘려 I/O 성능을 개선할 수 있습니다. 하지만 값이 커진 만큼 하나의 큐가 실행될 때 걸리는 시간이 늘어나므로() 일부 I/O에서 성능이 저하될 수 있습니다. slice_async_rq와 함께 고려하여 설정해야 합니다. (Default 8)
- low_latency : low latency mode를 enable/dsiable 합니다. enable인 경우 큐의 예상 처리 시간 target_latency 값보다 큰 경우 time_slice를 조정합니다. 각 큐에 time slice를 할당하기 전에 각 그룹 별(RT, BE, IDLE)로 요청 개수를 확인하고 해당 그룹의 큐를 모두 처리하는데 걸리는 시간인 expect_latency(=그룹 별 요청의 총합 * time slice)를 계산합니다. 이 계산 결과가 target_latency 값보다 크다면 이 값을 넘지않도록 time slice를 조정합니다. (Default 1 = enable)
- target_latency : low latency mode에서 time slice를 조절하기 위해 사용되는 예상 지연 시간입니다. (Default 300ms)
- slice_async : ASYNC 큐의 time slice를 계산하는 기준 값입니다. (Default 40ms)
- slice_async_rq : 1번의 time slice에서 dispatch 할 수 있는 ASYNC 요청의 최대 개수입니다. (Default 2)
- slice_idle : time slice 안에 큐의 모든 I/O 요청을 처리했을 때 다음 큐로 넘어가지 않고 대기하는 시간입니다. 대부분의 I/O 요청은 random access보다 sequential access가 많으므로 대기 시간을 주어 디스크 헤드의 이동을 최소화합니다. SSD의 경우 0, SAS/SATA의 경우 non-zero로 설정을 권고합니다. (Default 커널 버전에 따라 0 또는 8ms)
- slice_sync : SYNC 큐의 time slice를 계산하는 기준 값입니다. (Default 100ms)
group_isolation (Deprecated): 이 값이 0이면 SYNC_NOIDLE(임의 접근)에 속하는 큐들을 root cgroup으로 이동하여 처리합니다.
* 끝에 _us가 붙은 파라미터들은 ms대신 us로 설정하기 위한 파라미터 입니다.
Ex) slice_sync(100ms) ↔ slice_sync_us(100000us)
2. dealine I/O 스케줄러 [ non-miltiqueue ]
dealine 스케줄러는 I/O 요청별로 완료되어야 하는 deadline을 가지고 있으며 리눅스의 starvation problem에 대해 가장 빠른 스케줄러입니다.
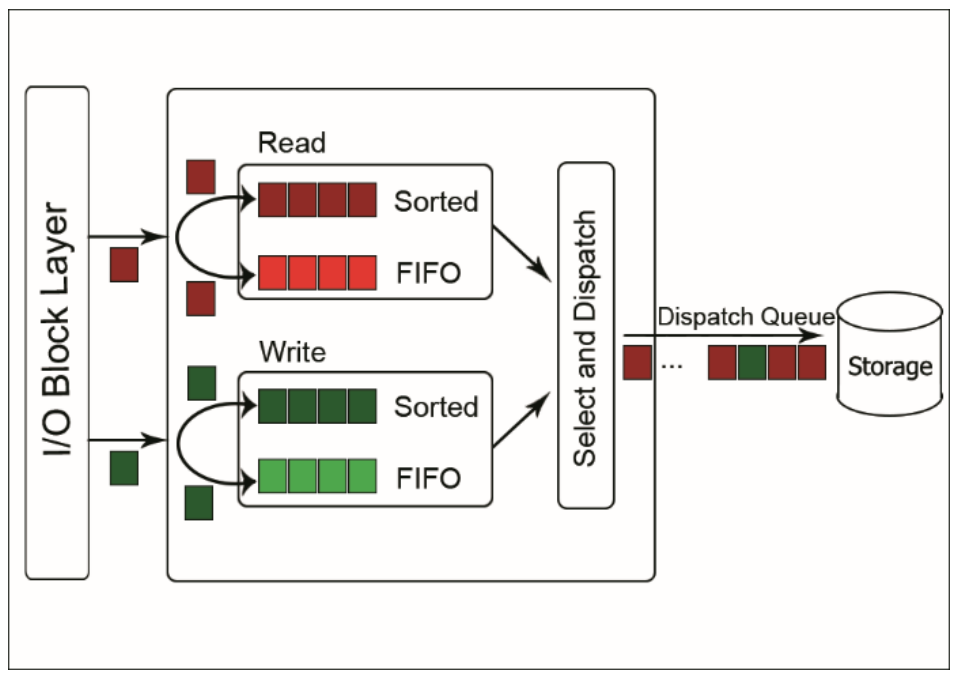
deadline 스케줄러에는 2개의 sotred list와 fifo list가 있습니다. sorted list는 각각 읽기 요청과 쓰기 요청을 저장하고 있으며 디스크 섹터를 기준으로 정렬됩니다. fifo list도 각각 읽기 요청과 쓰기 요청을 저장하지만 요청이 발생한 시간에 따른 deadline을 기준으로 정렬됩니다.
deadline 스케줄러에서 처리되는 I/O 요청이 deadline을 넘지 않는다면 sorted list의 순서대로 처리됩니다. 그러나 deadline을 초과한 I/O 요청이 발생하면 해당 요청을 먼저 처리합니다. 예를 들어, sorted list에 각 요청이 섹터 1, 10, 30, 50, 70에 해당하는 순서대로 정렬되어 있다고 가정하겠습니다. 이대로 deadline을 넘는 요청이 없다면 1→10→30→50→70의 순서대로 처리될 것입니다. 여기서 10번 블록의 요청을 처리한 후 50번 블록에 대한 요청에서 timeout이 발생했다면 해당 요청을 먼저 처리하기 위해 30→50→70의 순서가 아닌 50→30→70의 순서대로 재정렬됩니다.
* deadline 스케줄러의 파라미터
root@compute-1-1:~# ls /sys/block/sda/queue/iosched/
fifo_batch front_merges read_expire write_expire writes_starved
- fifo_batch : 한 번의 batch로 dispatch queue에서 실행할 I/O 요청의 개수를 의미합니다. 값이 낮을 수록 batch 당 처리량이 적으므로 latency가 적으며, 반대로 값이 크면 throughput이 증가합니다. (Default 16)
- front_merges : 디스크 헤드가 현재 섹터보다 앞쪽을 탐색하는 동작을 허용할 것인지 결정합니다. 시스템이 순차 읽기를 주로 수행한다면 값을 0으로 하여 앞쪽 탐색에 대한 오버헤드를 줄일 수 있습니다. (Default 1)
- read_expire : 읽기 요청에 대한 만료 시간입니다. fifo list에 인입된 이후 해당 시간동안 처리되지 않으면 sorted list에서 재정렬됩니다. (Default 500ms)
- write_expire : 쓰기 요청에 대한 만료 시간입니다. (Default 5000ms)
- writes_starved : 하나의 쓰기 batch를 작업하기 전에 몇 개의 읽기 batch를 작업을 상한으로 제한할 것인 결정합니다. deadline 스케줄러는 읽기 요청을 더 선호하기 때문에 쓰기 요청이 지연될 수 있습니다. 따라서 이 값을 수정해서 읽기와 쓰기 작업에 대한 밸런스를 조정할 수 있습니다. (Default 2)
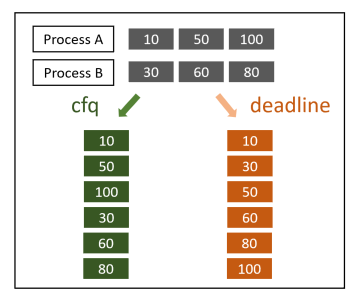
* CFQ vs Deadline
- 웹 서버
일반적으로 웹 서버에서 많이 발생하는 I/O 는 로그입니다. 로그는 파일의 끝에 계속 붙여 나가므로 순차 접근이 많으며, 파일 디스크립터를 여러 개 열어서 사용하지 않으므로 I/O 요청 자체도 많지 않습니다. 따라서 cfq와 deadline 스케줄러의 성능 차이가 거의 없습니다.
- 파일 서버
파일 서버에서는 다양한 접근이 이루어지기에 임의 접근이 많이 발생하며, 사용자 요청에 따라 많은 양의 I/O가 발생할 수 있습니다. 동영상 스크리밍이나 인코딩 서버 등 다수의 프로세스가 동등하게 I/O를 요청하는 경우 cfq 스케줄러의 성능이 우세합니다. 반면 DB와 같이 특정 프로세스가 많은 양의 I/O를 요청하는 경우, time slice에 따라 특정 프로세스의 I/O 요청이 처리되지 않는 idle time이 존재하지 않고 I/O 발생 시간을 기준으로 처리되기 때문에 deadline 스케줄러가 우세합니다.
3. noop I/O 스케줄러 [ non-multiqueue ]
noop 스케줄러는 정렬 없이 병합 작업만 하는 스케줄러로 아래의 경우에 주로 사용합니다.
- 다른 I/O 스케줄러와 성능을 비교
- Stoarge 자체에 스케줄러가 있는 경우(Intelligent storage 또는 multipath 환경)
- VM을 호스팅하는 경우 (Host와 VM의 스케줄러 각각 동작하므로 성능 저하가 발생할 수 있음)
- SSD를 사용하는 경우 (특정 섹터에 도달하는데 필요한 시간이 모두 동일하므로 불필요한 정렬 작업을 하지 않음)
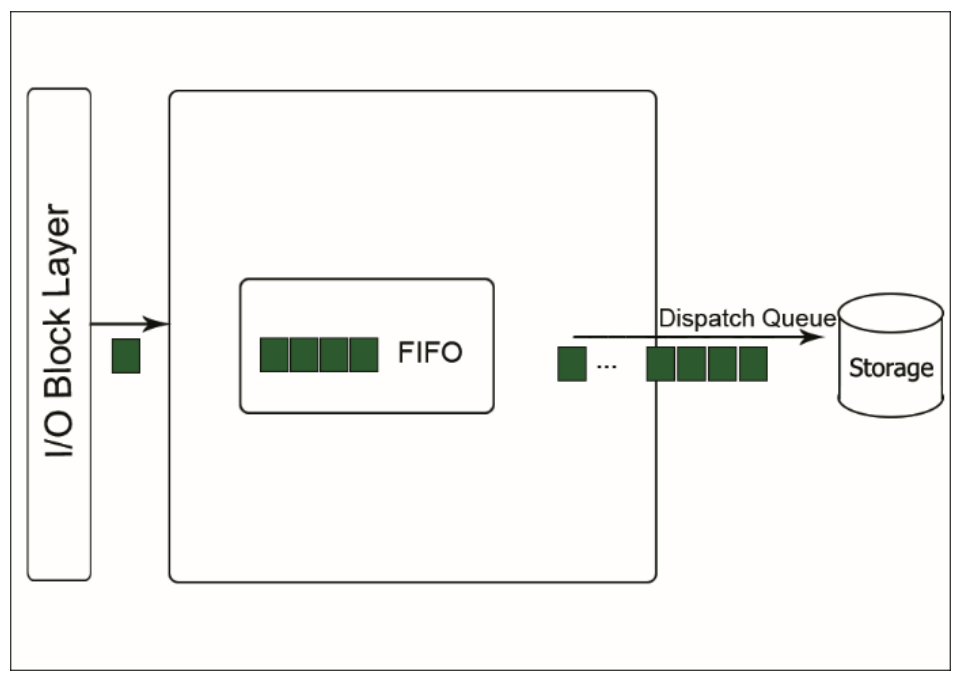
- Multiqueue 의 배경
기존으 HDD는 디스크 헤드가 물리적 이동 시간으로 인한 병목으로 random access에 한계가 존재했습니다. 그러나 멀티 프로세서 시스템과 SSD가 등장하고 성능이 점점 좋아지면서 병렬 처리와 함께 빠른 처리가 가능해졌지만 기존의 single queue에는 아래와 같은 문제가 있었습니다.
- 데이터 무결성을 위한 queue의 상호 배제에서 CPU 간 경합(contention) 발생.
- I/O request queue를 처리하는 CPU(아래 그림의 CPU 0)에서 인터럽트로 인한 잦은 context switching가 발생하는 문제.
- 멀티 프로세서 환경으로 인한 NUMA의 Remote Access 문제.
- 코어 수의 상승에 따른 동작 프로세스와 I/O요청의 증가와 저장 장치의 IOPS(I/O per sec) 사이에서 queue의 밸런스 문제.
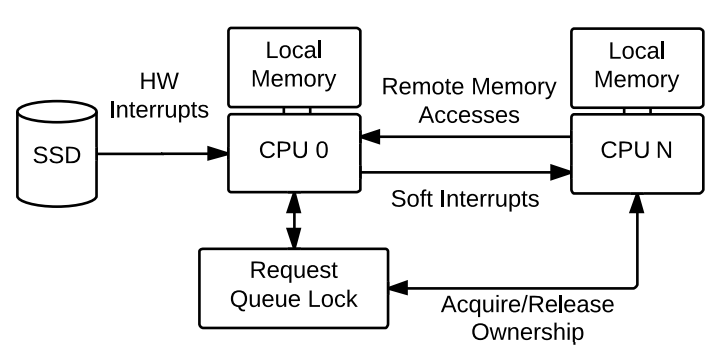
결국 single queue는 또다른 병목이 되었고 이러한 문제를 개선하기 위해 software staging queue와 hardware dispatch queue 이렇게 2가지의 queue를 가진 multiqueue(mq)가 등장하였습니다.
software staging queue는 CPU core또는 소켓 단위에 매핑되어 각 프로세스들의 I/O 요청을 buffering하고 인접한 섹터의 요청들을 병합하여 I/O를 스케줄링 합니다. 이후 각 스케줄러의 로직에 맞게 처리한 이후 자신과 매핑된 hardware dispatch queue로 보냅니다.
hardware dispatch queue는 저장장치의 버퍼가 넘치지 않도록 속도를 조절하여 I/O 요청을 드라이버(Submission queue)로 넘겨줍니다. hardware queue의 개수는 driver마다 다르지만 최대 CPU core개수를 넘을 수 없습니다.
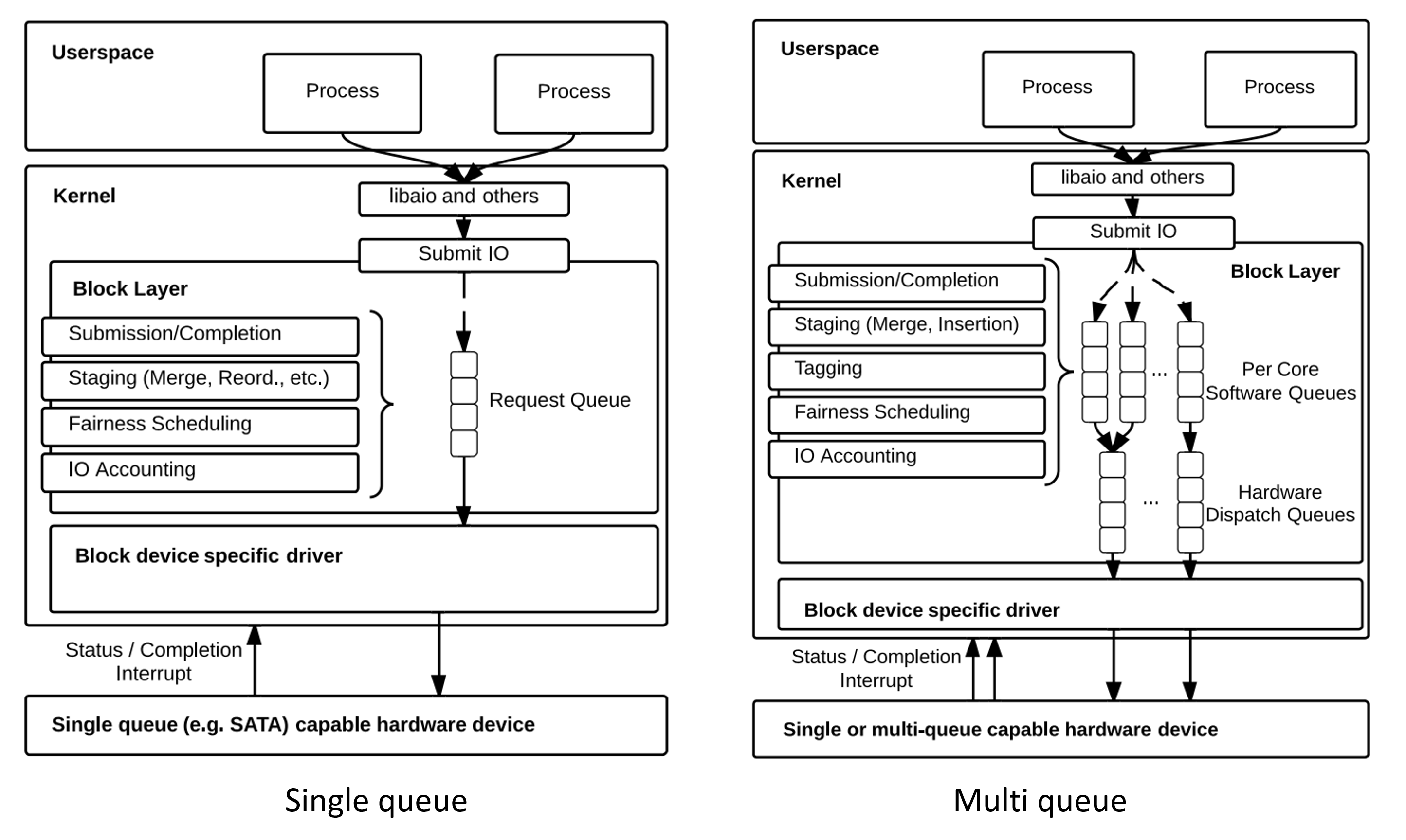
또한 multi-queue는 single-queue와 달리 I/O에 tagging을 사용합니다. Driver는 userspace에서 요청한 I/O 작업을 끝내면 고유 정수값을 completion tag로 사용하여 block layer에 넘겨줌으로써 어떤 I/O 요청에 완료되었는지 탐색하는 작업을 줄일 수 있습니다.
4. mq-deadline I/O 스케줄러 [ multiqueue ]
기존의 deadline 스케줄러와 동일하지만 multiqueue로 병렬 처리를 활용합니다. deadline을 초과한 I/O를 software queue에서 재정렬하여 hardware queue로 넘겨줍니다.
master-1:# ls /sys/block/sda/queue/iosched/
async_depth fifo_batch front_merges read_expire write_expire writes_starved- async_depth : 동시에 처리할 수 있는 ASYNC(쓰기 작업)의 최대 개수를 정의합니다. (Default 48)
5. none I/O 스케줄러 [ multiqueue ]
FIFO로 구현되어 있으며 noop 스케줄러와 유사합니다. 주로 스케줄링 자체에 대한 오버헤드를 줄이기위해 사용합니다.
6. BFQ(Budget Fair Queueing) I/O 스케줄러 [ multiqueue ]
BFQ 스케줄러는 CFQ 기반이지만 고정된 time slice가 아니라 섹터의 수에 따라 계산되는 budget을 각 프로세스에 할당하여 I/O batch를 스케줄링합니다. 이로써 하나의 Application이 모든 I/O 대여폭을 사용하지 못 하도록 보장하며, I/O 처리량보다는 낮은 Latency에 더 초점을 맞춥니다. 주로 스트리밍 서비스, packet dump(SPAN)와 같이 latency나 loss에 민감한 real-time 시스템에 적합합니다.
* bfq 스케줄러의 파라미터
master-1:# ls /sys/block/sda/queue/iosched/
back_seek_max back_seek_penalty fifo_expire_async fifo_expire_sync low_latency max_budget slice_idle slice_idle_us strict_guarantees timeout_sync
- slice_idle : cfq 참조. 단일 queue인 CFQ와 달리 multi-queue인 BFQ의 경우, idle time을 주어 한 프로세스 A가 요청한 I/O 요청이 queue A에서 처리되는 중간에 또 다른 queue B에 의한 다른 I/O 요청이 dispatch되지 않도록합니다. 이렇게하여 프로세스 A의 I/O 요청은 연속성을 보장받을 수 있으며 순차 작업에 대한 처리량도 기대할 수 있게 됩니다. 그러나, 임의 작업의 경우에는 idle time에 따른 처리량 저하가 발생할 수 있습니다. (Default 8ms)
- strict_guarantees : 이 값이 set인 경우 bfq는 queue가 비워질 때 마다 항상 idle time을 가집니다. 그리고 지연되는 요청이 따로 없다면 저장 장치가 한번에 1개의 I/O요청을 처리하도록 합니다. slice_idle는 dispatch 순서를 보장하고, strict_guarantees는 실제 I/O가 처리되는 순서를 보장합니다. (Default 0 = unset)
- low_latency : cfq와 참조 (Default 'enabled')
- timeout_sync : 1개의 Task(Queue)가 처리될 수 있는 최대 시간입니다. 탐색 시간이 긴 저장장치는 이 값을 늘려서 처리량을 개선할 수 있습니다. 반대로 탐색 시간이 짧은 장치의 경우, 하나의 task가 CPU를 점유하는 시간이 길어지므로 Latency가 길어질 수 있습니다. (Default 124ms)
- max_budget : timeout_sync 동안 처리될 수 있는 최대 섹터의 개수(Budget)입니다. 순차 접근이 많은 시스템에서는 이 값을 늘려서 처리량을 개선할 수 있지만, Latency가 길어질 수 있습니다. (Default 0 = auto-tuning enable )
- back_seek_max : cfq와 참조 (Default 16384 = 16KB)
- back_seek_penalty : cfq와 참조 (Default 2)
- fifo_expire_asnyc : cfq와 참조 (Default 250ms)
- fifo_expire_sync : cfq와 참조 (Default 125ms)
* cgroup supprt
bfq는 cgroup-v1/2 모두 지원하는 스케줄러로 cgroup마다 weight를 주어 전체 I/O 대역폭을 일정 비율로 공유하여 사용할 수 있습니다.
master-1:~ # cat /sys/fs/cgroup/blkio/kubepods.slice/blkio.bfq.weight
136- blkio.bfq.weight : cgroup-v1에서의 weight 설정입니다. low-latency가 enable으면 스케줄러가 자동으로 이 값을 변경합니다. (Default 100)
- io.bfq.weight : cgroup-v2에서의 weight.
- blkio.bfq.weight_device : 저장 장치마다 wieght를 설정할 수 있습니다.
7. kyber I/O 스케줄러 [ multiqueue ]
kyber 스케줄러는 동기작업인 read와 비동기작업인 write에 해당하는 2개의 queue로 구성됩니다. 그리고 각 작업의 target latency를 설정하고 이를 충족하기 위해 동적으로 I/O 요청을 throttling 합니다. 여기서 kyber는 토큰을 사용하여 I/O 처리 시간을 제한합니다. 그리고 Read와 Write에 해당하는 각 토큰이 유효할 때 까지 round-robin으로 hardware queue로 dispatch 합니다. 토큰의 개수가 많을 수록 I/O 작업을 보장받을 수 있는 시간이 길어지므로 target latency를 달성하기 쉬워집니다.
현재 I/O의 latency가 target latnecy보다 작다면, 이미 target latency를 달성하고 있으므로 현재 토큰 개수를 유지합니다. 반대로, 현재 I/O latency가 target latnecy보다 크다면 토큰의 개수를 증가시켜서 I/O 작업 시간을 늘려 target latency를 달성할 수 있도록 합니다.
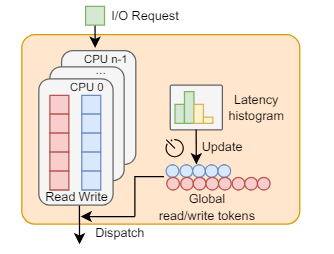
현재 latecny > target latency → 토큰 갯수 증가
현재 latency < target latency → 토큰 갯수 유지
master-1:# ls /sys/block/sda/queue/iosched/
read_lat_nsec write_lat_nsec- read_lat_nsec : 동기작업 read의 target latency입니다. (Default 2000000ns = 2ms)
- write_lat_nsec : 비동기작업 write의 target latency입니다. (Default 10000000ns = 10ms)
마치며...
스케줄러 성능 비교를 위해 참고했던 두 자료에서 서로 다른 결과 나왔습니다. 변인이나 기준이 달라서 비교하기는 어렵지만, SSD의 성능이 좋아 질수록 구현이 단순한 Kyber가 locking 등으로 CPU 오버헤드가 있는 mq-deadline과 bfq보다 상대적으로 뛰어난 성능을 보여주는 듯 합니다. 그리고 이제는 I/O의 병목이 디스크가 아닌 CPU라고 얘기하기도 하네요.
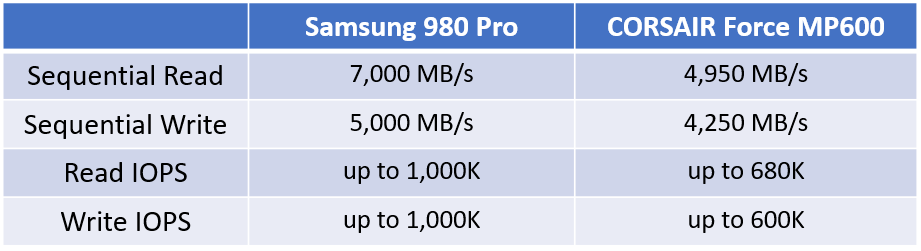
I/O 스케줄러 BMT with CORSAIR SSD (2020)
I/O 스케줄러 BMT with 삼성 SSD (2024)
Reference
https://ji007.tistory.com/entry/IO-Schedulers
I/O Schedulers
I/O Scheduler 는 block layer에 해당하며 file system으로부터 bio structure에 대한 request submit 을 받아 Block I/O에 대한 동작 요청을 I/O Request queue로 전달하는 역할을 한다. I/O Request queue에 전달된 I/O는 device dr
ji007.tistory.com
https://blog.mi.hdm-stuttgart.de/index.php/2022/04/01/improve-your-storage-i-o-performance-today/
Improve your storage I/O performance today | Computer Science Blog @ HdM Stuttgart
an article by Lucas Crämer and Jannik Smidt DISCLAIMER This post tries to keep the complexity manageable while making a point clear. We are not systems engineers/kernel developers, so feel free to point out any mistakes/misunderstandings. This post probab
blog.mi.hdm-stuttgart.de
https://blog.csdn.net/weixin_33963189/article/details/92562519
linux io过程自顶向下分析-CSDN博客
前言 IO是操作系统内核最重要的组成部分之一,它的概念很广,本文主要针对的是普通文件与设备文件的IO原理,采用自顶向下的方式,去探究从用户态的fread,fwrite函数到底层的数据是如何
blog.csdn.net
https://www.kernel.org/doc/Documentation/block/cfq-iosched.txt
https://dergipark.org.tr/tr/download/article-file/595488
6.4. Configuration Red Hat Enterprise Linux 6 | Red Hat Customer Portal
Access Red Hat’s knowledge, guidance, and support through your subscription.
access.redhat.com
Chapter 12. Setting the disk scheduler Red Hat Enterprise Linux 8 | Red Hat Customer Portal
Access Red Hat’s knowledge, guidance, and support through your subscription.
access.redhat.com
https://wiki.ubuntu.com/Kernel/Reference/IOSchedulers
Kernel/Reference/IOSchedulers - Ubuntu Wiki
Linux I/O schedulers I/O schedulers attempt to improve throughput by reordering request access into a linear order based on the logical addresses of the data and trying to group these together. While this may increase overall throughput it may lead to some
wiki.ubuntu.com
https://documentation.suse.com/ko-kr/sles/12-SP5/html/SLES-all/cha-tuning-io.html
Tuning I/O Performance | SLES 12 SP5
I/O scheduling controls how input/output operations will be subm…
documentation.suse.com
https://www.kernel.org/doc/html/latest/block/index.html
Block — The Linux Kernel documentation
www.kernel.org
https://documentation.suse.com/sles/15-SP2/html/SLES-all/cha-tuning-cgroups.html
Kernel Control Groups | SLES 15 SP2
Kernel Control Groups (cgroups) are a kernel feature that allows…
documentation.suse.com
https://atlarge-research.com/pdfs/2024-io-schedulers.pdf
https://marc.info/?l=linux-block&m=149180716319351&w=2
'[PATCH v3 5/5] blk-mq: introduce Kyber multiqueue I/O scheduler' - MARC
marc.info
https://www.phoronix.com/review/linux-56-nvme
Linux 5.6 I/O Scheduler Benchmarks: None, Kyber, BFQ, MQ-Deadline - Phoronix
While some Linux distributions are still using MQ-Deadline or Kyber by default for NVMe SSD storage, using no I/O scheduler still tends to perform the best overall for this speedy storage medium. In curious about the current state of the I/O schedulers wit
www.phoronix.com
'System Engineering > Linux' 카테고리의 다른 글
| [커널이야기] TCP Keepalive와 Retransmission (0) | 2023.09.26 |
|---|---|
| [커널이야기] TCP handshake와 TIME_WAIT 소켓 (0) | 2023.09.23 |
| [Linux] NTPv4(RFC5905)와 chrony 그리고 timex (0) | 2023.07.21 |
| [커널이야기] 리눅스 더티 페이지와 I/O Throttling (0) | 2023.07.06 |
| [커널이야기] 리눅스 메모리 1 - 메모리를 확인하는 방법과 slab/swap 메모리 (2) | 2023.06.15 |