
이전 내용(TCP handshake와 TIME_WAIT 소켓)에 이어 작성합니다.
목차
- TCP keepalive
- Keepalive와 좀비 커넥션
- TCP keepalive vs HTTP keepalive
- Keepalive와 Load Balancer - keepalive로 해결 가능한 문제
- TCP Retransmission과 RTO
- 재전송과 커널 파라미터 그리고 tcp_write_timeout() 함수
- RTO_MIN 변경하기
- TCP 재전송과 Application Timeout
1. TCP keepalive
keepalive란 한 번 맺은 세션의 요청이 끝나더라도 타이머에 따라 아주 작은 사이즈의 패킷을 보내어 연결을 유지해주는 기능입니다. 클라이언트의 잦은 요청으로 세션을 맺고 끊는 횟수가 많을 경우, 그 연결을 끊지 않고 유지하고 지속적으로 요청을 처리하여 불필요한 handshake와 TIME_WAIT 소켓을 줄이고 서버의 성능을 향상시킬 수 있습니다.
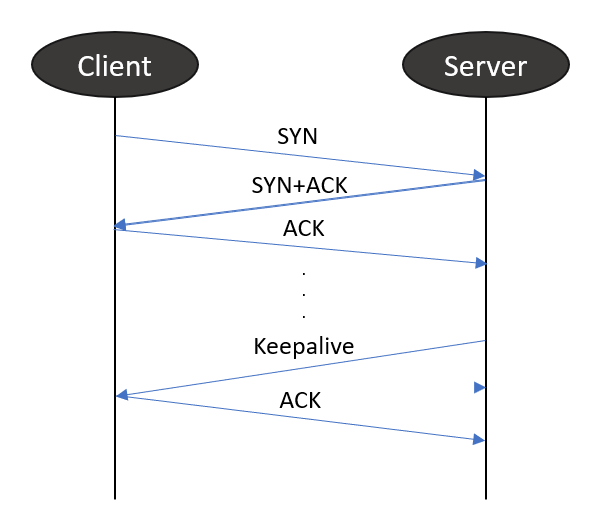
netstat 명령어로 keepalive의 타이머 시간을 확인할 수 있으며, 커널에서는 TCP keepalive와 관련하여 아래 3개지 파라미터를 제공합니다.
root@server:~$ netstat -napo
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name Timer
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN - off (0.00/0/0)
... # 타이머의 남은 시간
tcp 0 0 192.168.0.10:22 192.168.1.111:59319 ESTABLISHED - keepalive (160.88/0/0)
tcp 0 0 192.168.0.10:34110 192.168.0.11:22 ESTABLISHED 70390/ssh keepalive (4818.35/0/0)
tcp 0 0 192.168.0.10:22 192.168.1.111:53835 ESTABLISHED - keepalive (539.13/0/0)
tcp 0 0 192.168.0.10:55328 192.168.0.11:22 ESTABLISHED 69385/ssh keepalive (1599.51/0/0)root@\server:~# sysctl -a | grep keepalive
net.ipv4.tcp_keepalive_intvl = 75 # keepalive 패킷 재전송 주기
net.ipv4.tcp_keepalive_probes = 9 # keepalive 패킷의 최대 전송 횟수
net.ipv4.tcp_keepalive_time = 7200 # keepalive 소켓 유지 시간
2. Keepalive와 좀비 커넥션
keepalive를 사용하는 가장 큰 이점은 좀비 커넥션을 방지하는 것입니다.
아래 그림처럼 클라이언트와 서버가 TCP 세션을 맺고 있다가 어떤 이유로 한 쪽(클라이언트)이 FIN이나 RST를 받지 못한 채로 상대방(서버)이 응답 불가가 된 경우, 클라리언트는 소켓을 점유한 채 일정 시간을 기다려야합니다. 그러나 keepalive 기능을 사용하여 keepalive 패킷으로 보내고, 타이머와 probe 횟수 이내에 응답을 받지 못하면 RST를 보내고 소켓을 닫아 이를 방지할 수 있습니다.
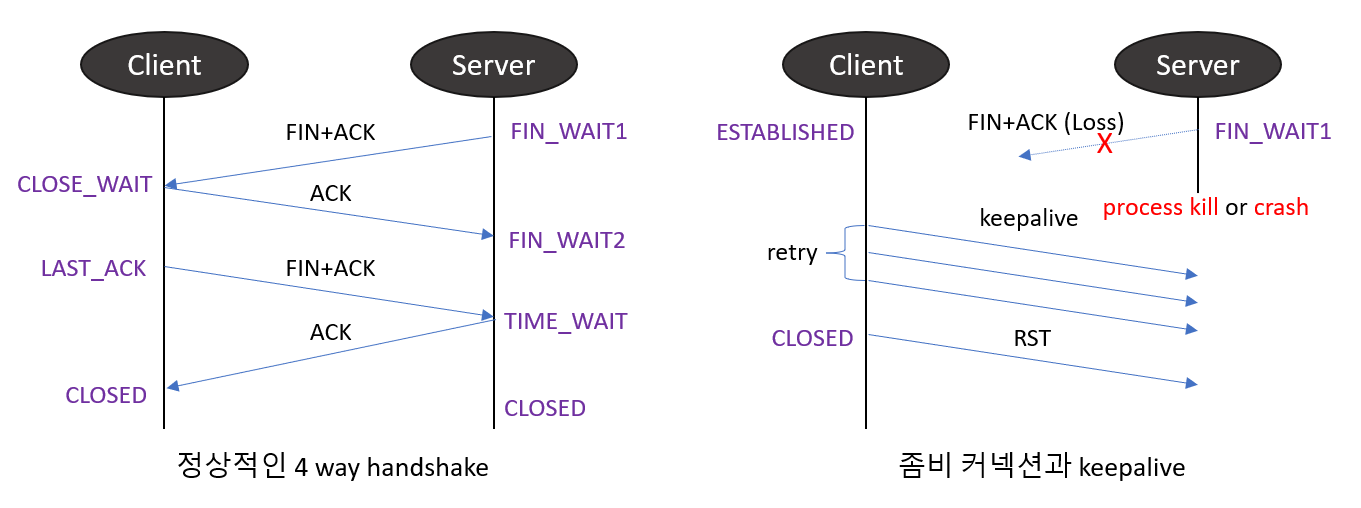
이처럼 TCP keepalive를 사용하면 어플리케이션에서 별도로 구현하지 않더라도 커널 단에서 세션을 관리할 수 있습니다.
3. TCP keepalive vs HTTP keepalive
apache나 nginx와 같은 어플리케이션에서도 HTTP/1.1에서 지원하는 keepalive 설정이 있습니다. 이는 End-to-End 연결을 위해 작은 사이즈의 패킷을 주기적으로 주고 받아 연결과 소켓을 확인하는 TCP keepalive와 달리, HTTP Request에 keep-alive 헤더를 추가해서 보내면 서버는 timoue과 max를 찍어서 응답합니다.
# keep-alive 헤더를 추가한 요청에 대한 Apache 서버의 응답
root@server:~$ curl -kv {URL} -H "Connection: keep-alive"
...
< HTTP/1.1 200 OK
< Date: Fri, 29 Sep 2023 23:44:20 GMT
< Server: Apache
...
< Keep-Alive: timeout=60, max=100
< Connection: Keep-Alive
< Content-Type: application/json; ...* timeout : 커넥션이 몇 초 동안 유지 될 것인지
* max : 커넥션을 통해 주고 받을 수 있는 request의 최대 갯수.
위의 경우 60초 동안 연결을 유지하고, 다음 60초 이내 요청이 없다면 연결을 종료합니다. 또한 60초 이내더라도 100개의 트랜잭션을 초과하게 되며 연결을 종료합니다.
TCP keepalive > HTTP keepalive인 경우에도 HTTP keepalive에 의해 연결을 끊어버립니다.
* Keepalive와 Load Balancer - keepalive로 해결 가능한 문제
로드 밸런서의 여러 구조 중 Inline 구조와 DSR 구조가 있습니다.
먼저 Inline 구조의 경우 클라이언트의 요청과 서버의 응답모두 로드 밸런서를 거치는 구조입니다. Inbound와 Outbound 패킷 모두 로드 밸런서를 거치기 때문에 트래픽 부하가 크지만, 패킷의 모니터링과 필터링에 유리합니다. 삼중화로 구성된 쿠버네티스의 마스터 노드에서 kube-apiserver의 로드 밸런싱을 위해 keepalived와 haproxy처럼 소규모의 management traffic이 흐르면서 모니터링이 중요한 시스템에 적합합니다.
DSR(Direct Server Return) 구조는 클라이언트의 요청에 대한 서버의 응답이 로드 밸런서를 거치지 않고 직접 전달됩니다. 로드 밸런서와 서버가 같은 네트워크에 속해야 한다는 제약이 있지만, 로드 밸런서를 거치는 패킷이 줄어드는 만큼 트래픽 부하를 줄일 수 있어 대규모 서비스에서 많이 사용됩니다.
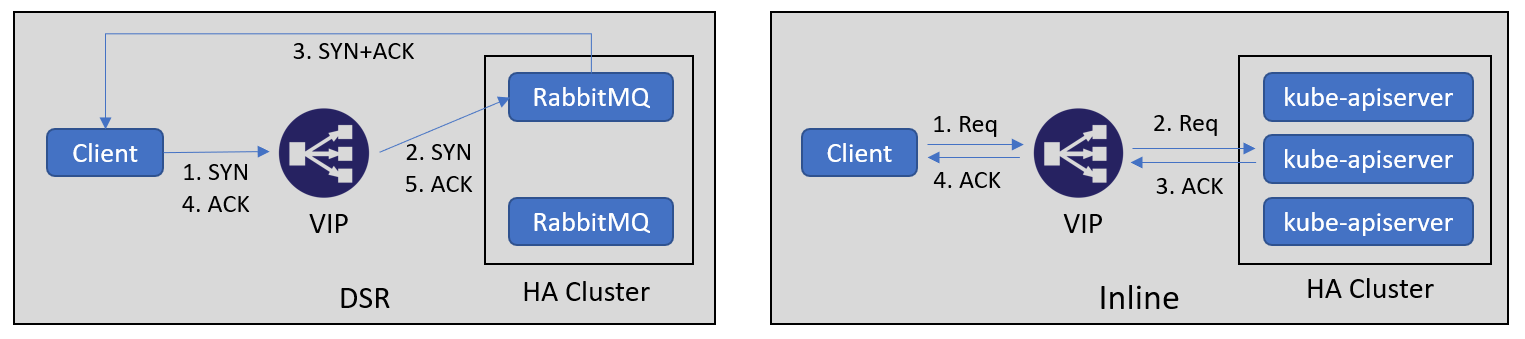
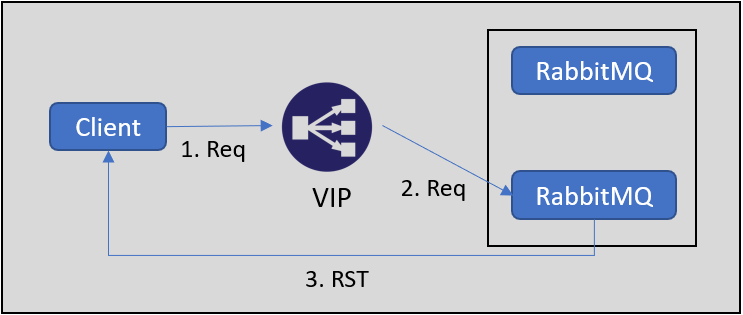
여기서 keepalive로 해결 가능한 문제는 DSR 구조에서 발생합니다. DSR 구조에서 사용자가 적은 새벽시간대에 일정 시간동안 연결된 세션에 대해서 로드밸런서로 패킷이 흐르지 않으면 로드 밸런서의 idle timeout에 의해 세션 테이블이 삭제됩니다. 클라이언트 입장에서는 여전히 세션이 유지되고 있기 때문에 새로운 요청을 보내지만, 이미 로드 밸런서의 세션 테이블에서 삭제되었으므로 새로운 세션으로 간주됩니다. 만약 새로운 요청이 기존과 다른 서버로 요청이 유입되었다면 서버 입장에서는 TCP handshake 과정이 없었던 세션의 데이터 요청으로 간주하고 RST를 보내게 됩니다.
nginx, istio, haproxy에서 session idle timeout (작성중입니다.)
2. TCP Retransmission과 RTO (Retransmission Timeout)
TCP는 송신자가 보낸 패킷에 대한 ACK 패킷을 받아아 통신이 정상적으로 이루어졌다고 간주합니다. 그래서 송신자가 패킷을 보내고 거기에 대한 ACK를 받지 못하면 패킷이 유실된 것으로 판단하고 패킷을 재전송합니다. 여기서 ACK를 기다리는 타이머에 대한 값을 RTO라고 합니다.
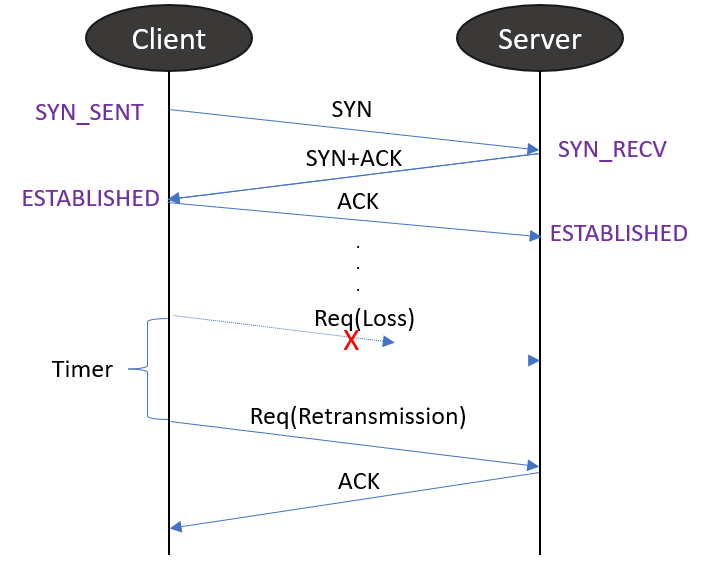
RTO에는 RTO와 initRTO 두 가지가 있습니다. 일반적인 RTO는 End-to-End 간의 RTT(Round Trip Time)를 기준으로 설정됩니다. 그리고 initRTO는 TCP handshake가 발생하는 첫 SYN 패킷에 대한 RTO를 의미합니다. 세션을 맺는 첫 단계이기에 RTT를 알 수 없기 때문에 리눅스에서는 initRTO가 1초로 하드 코딩되어 있습니다.
그리고 TCP 세션의 RTT와 RTO 값은 ss 명령어로 확인할 수 있습니다.
root@server :~> ss -i
tcp ESTAB 0 0 192.168.100.100:60990 192.168.100.101:etcd-server
cubic wscale:11,11 rto:204 rtt:0.082/0.028 ato:40 mss:1024 pmtu:9000 rcvmss:1340 advmss:8960 cwnd:10 bytes_sent:1778 bytes_acked:1779 bytes_received:16992591157 segs_out:165276289 segs_in:165458279 data_segs_out:4 data_segs_i
n:165458274 send 999Mbps lastsnd:2573705048 lastrcv:148 lastack:376 pacing_rate 2Gbps delivery_rate 193Mbps delivered:5 app_limited rcv_rtt:3217.79 rcv_space:117305 rcv_ssthresh:415696 minrtt:0.049
tcp ESTAB 0 0 127.0.0.1:etcd-client 127.0.0.1:50640
cubic wscale:11,11 rto:212 rtt:9.523/15.989 ato:40 mss:1024 pmtu:65535 rcvmss:1024 advmss:65495 cwnd:10 bytes_sent:81264639 bytes_retrans:85 bytes_acked:81264554 bytes_received:42645091 segs_out:1409087 segs_in:2090909 data
_segs_out:1408821 data_segs_in:686052 send 8.6Mbps lastsnd:2724 lastrcv:2724 lastack:2680 pacing_rate 17.2Mbps delivery_rate 1.37Gbps delivered:1408822 app_limited busy:9396380ms retrans:0/2 dsack_dups:2 rcv_rtt:387232 rcv_space:657
62 rcv_ssthresh:73687 minrtt:0.009위의 두 세션은 204ms와 212ms 동안 ACK를 받지 못하면 패킷을 재전송하게 됩니다. 그리고 rtt로 출력된 값은 평균값/평균편차를 의미합니다. 두 세션이 하나의 패킷을 주고 받기위해 평균적으로 0.082ms와 9.523ms가 소요됩니다.
* RTO 값은 재전송 될 때마다 2배씩 증가합니다.
3. 재전송과 커널 파라미터 그리고 tcp_write_timeout() 함수
리눅스 커널에서는 TCP 재전송에 대해 아래 5가지의 파라미터를 제공합니다.
root@server:~ # sysctl -a | grep retries
net.ipv4.tcp_syn_retries = 8 # SYN에 대한 retry 횟수
net.ipv4.tcp_synack_retries = 5 # 상대방의 SYN에 대한 SYN+ACK의 retry 횟수
net.ipv4.tcp_orphan_retries = 0 # FIN_WAIT1 상태에서 FIN에 대한 retry 횟수
net.ipv4.tcp_retries1 = 3 # IP Layer에 문제가 있는지 확인(Soft Threshold)
net.ipv4.tcp_retries2 = 15 # 통신이 가능한지 확인(Hard Threshold) -> 해당 횟수 초과 시 연결 종료그리고 커널 파라미터의 재전송 횟수는 tcp_write_timeout() 함수에 반영됩니다.
tcp_timer.c에 정의된 tcp_write_timeout() 함수는 위의 커널 파라미터를 반영하여 재전송 횟수와 타이머를 기준으로 소켓을 종료할지 말지를 결정합니다.
// net/ipv4/tcp_timer.c
static int tcp_write_timeout(struct sock *sk) {
struct inet_connection_sock *icsk = inet_csk(sk);
struct tcp_sock *tp = tcp_sk(sk);
struct net *net = sock_net(sk);
bool expired = false, do_reset;
int retry_until;
if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
if (icsk->icsk_retransmits)
__dst_negative_advice(sk);
retry_until = icsk->icsk_syn_retries ? :
READ_ONCE(net->ipv4.sysctl_tcp_syn_retries);
// 소켓의 상태가 SYN_SENT 또는 SYN_RECV 상태일 경우 tcp_syn_retries 값 반영
expired = icsk->icsk_retransmits >= retry_until;
// retry 횟수보다 재전송 횟수가 크거나 같다면 expired로 판단.
} else {
if (retransmits_timed_out(sk, READ_ONCE(net->ipv4.sysctl_tcp_retries1), 0)) {
// retransmits_timed_out() : 패킷 전송 시간을 기준으로 ACK를 받기 전에 타이머가 만료되면, timeout으로 판단.
tcp_mtu_probing(icsk, sk);
// sysctl_tcp_mtu_probing 파라미터에 따라 동작 (default = disabled)
// 재전송 전에 두 종단 사이 Network MTU에 의한 Fragment 방지를 위한 MSS negotiation
__dst_negative_advice(sk);
// 목적지 IP와 next-hop 등이 포함된 dst_entry 구조체(destination cache)에 negative flag를 줌
}
retry_until = READ_ONCE(net->ipv4.sysctl_tcp_retries2);
if (sock_flag(sk, SOCK_DEAD)) {
const bool alive = icsk->icsk_rto < TCP_RTO_MAX;
// 소켓이 죽은 상태에서 RTO의 값이 RTO_MAX(120s)보다 작다면 alive 상태로 간주.
retry_until = tcp_orphan_retries(sk, alive);
// orphan socket 상태이므로 sysctl_tcp_retries2 대신 tcp_orphan_retries 값 적용.
...
}
}
if (!expired) //
expired = retransmits_timed_out(sk, retry_until, icsk->icsk_user_timeout);
...
if (expired) {
// retry 횟수 이내에 ACK를 받지 못 했다면 에러 정보를 저장하고 소켓 종료
tcp_write_err(sk);
return 1;
...
}
* tcp_synack_retries 와 SYN flooding
서버가 SYN을 받고 SYN+ACK를 전송하면 소켓은 SYN_RECV 상태가 됩니다. DDoS의 일종인 SYN flooding 공격은 3 way handshake 과정에서 클라이언트(좀비 단말)가 다량의 SYN을 보내고 서버의 SYN+ACK에 응답하지 않도록 합니다. 그러면 서버는 클라이언트로부터 받은 SYN에 SYN+ACK를 보내지만 ACK를 받지 못해 tcp_synack_retries에 정의된 횟수 만큼 SYN+ACK를 재전송하며 SYN_RECV 상태를 유지합니다. 이는 서버 리소스 고갈로 이어질 수 있으므로 tcp_synack_retries 값을 적절하게 줄이는 것이 좋습니다.
* tcp_orphan_retries와 orphan socket
FIN_WAIT, TIME_WAIT 상태의 소켓들은 커널에 반환되어 정리되기를 기다리는 상태입니다. TCP 연결을 끊기 위한 4 way handshake 과정에서 서버는 FIN을 보낸 이후에는 받는 패킷만 존재하므로 tcp_orphan_retries 값은 FIN_WAIT1 소켓에만 해당됩니다. 즉, FIN_WAIT1 상태의 소켓이 바로 orphan socket입니다.
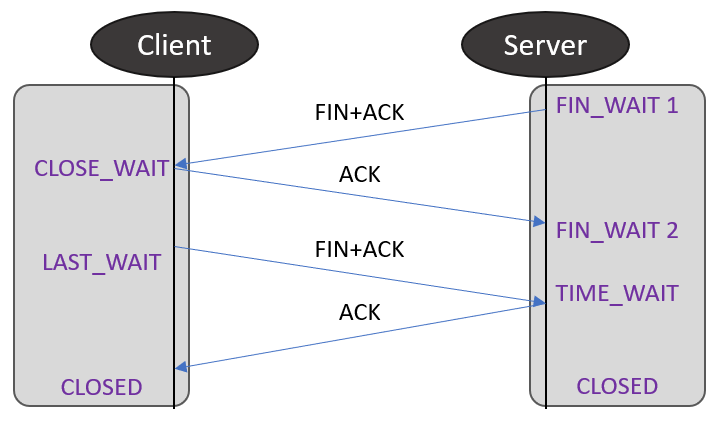
tcp_orphan_retries 값은 tcp_orphan_retires() 함수에서 사용됩니다.
// net/ipv4/tcp_timer.c
/**
* tcp_orphan_retries() - Returns maximal number of retries on an orphaned socket
* @sk: Pointer to the current socket.
* @alive: bool, socket alive state
*/
static int tcp_orphan_retries(struct sock *sk, bool alive) {
int retries = READ_ONCE(sock_net(sk)->ipv4.sysctl_tcp_orphan_retries); /* May be zero. */
/* We know from an ICMP that something is wrong. */
if (sk->sk_err_soft && !alive)
retries = 0;
/* However, if socket sent something recently, select some safe number of retries.
* 8 corresponds to >100 seconds with minimal RTO of 200msec. */
if (retries == 0 && alive)
retries = 8;
return retries;
}tcp_orphan_retries 값이 0이고 소켓이 alive 상태이면 retry 값으로 8을, 파라미터의 값이 0이 아니라면 해당 값을 retry 값으로 반환합니다. 그리고 소켓의 alive 상태는 위의 tcp_write_timeout() 함수에 정의되어 있습니다. orphan socket 상태 소켓의 RTO 값이 TCP_RTO_MAX(120s)보다 크다면 0이 되어 False가 됩니다. 그러나 RTO가 120s보다 클 일은 거의 없기에 해당 값은 거의 항상 1이 됩니다.
FIN_WAIT1 상태에서 지정된 횟수만큼 FIN을 재전송해서 ACK를 받지 못하면 FIN_WAIT2나 TIME_WAIT 상태로 변경 없이 바로 소켓을 회수합니다. 그렇기에 tcp_orphan_retries 값이 너무 작으면 FIN_WAIT1 소켓이 너무 빨리 정리 되어 상대편에서 소켓이 닫히지 않는 결과가 될 수 있습니다. 따라서 TIME_WAIT 상태가 유지되는 60초 정도가 될 수 있는 7 정도의 값으로 설정하는 것이 좋습니다.
* tcp_retries1 vs tcp_retries2 (RFC-1122)
아래는 ubuntu에서 man tcp 명령어로 볼 수 있는 설명입니다.
tcp_retries1 (integer; default: 3; since Linux 2.2)
The number of times TCP will attempt to retransmit a packet on an established connection normally, without the extra effort of getting the network layers involved. Once we exceed this number of retransmits, we
first have the network layer update the route if possible before each new retransmit. The default is the RFC specified minimum of 3.
tcp_retries2 (integer; default: 15; since Linux 2.2)
The maximum number of times a TCP packet is retransmitted in established state before giving up. The default value is 15, which corresponds to a duration of approximately between 13 to 30 minutes, depending on the
retransmission timeout. The RFC 1122 specified minimum limit of 100 seconds is typically deemed too short.tcp_retries1(R1)은 retransmits_timed_out() 함수를 통해 해당 connection이 timeout 된 것으로 판단되면 dst_negative_advice() 함수를 호출합니다. dst_negative_davice() 함수는 목적지 IP와 next-hop(gateway), timestamp 등의 정보를 담고 dst_entry 구조체(destination cache)에 negative flag를 줍니다. (Soft threshold)
tcp_retries2(R2)은 retry_until 값에 반영되어 retransmits_timed_out() 함수를 통해 connection이 expired인지 확인하는 용도로 사용됩니다. (Hard threshold)
결과적으로 tcp_retires2 값에 정의된 횟수를 초과해야 세션을 종료합니다.
4. RTO_MIN 변경하기
RTO_MIN의 값은 tcp.h에 200ms로 정의되어 있습니다. RTT가 작은 내부망 통신이라도 RTO값은 200ms보다 작아질 수 없습니다.
// include/net/tcp.h
#define TCP_RTO_MAX ((unsigned)(120*HZ))
#define TCP_RTO_MIN ((unsigned)(HZ/5))
/* HZ는 보통 1초 */
/* RTO_MAX = 120s & RTO_MIN = 200ms */
그러나 ip route 명령어의 rto_min 옵션을 통해 RTO_MIN 값을 변경할 수 있습니다. 세션별로는 바꿀 수 없으며 하나의 NIC 인터페이스를 기준으로 변경할 수 있습니다.
root@sevrer:~ # ip route change default via <GW> dev <DEVICE> rto_min 100ms아래 명령어를 통해 eth0를 통해 연결된 ssh 세션의 rto 값이 156이 된 것을 확인할 수 있습니다.
root@sevrer:~ # ip route change 192.168.100.0/24 dev eth0 rto_min 150ms
root@sevrer:~ # ip route
...
192.168.100.0/24 dev eth0 proto kernel scope link src 192.168.100.104 rto_min lock 150ms
...root@sevrer:~ # ss -i
tcp ESTAB 0 0 192.168.100.104:ssh 192.168.100.100:64912
cubic wscale:11,11 rto:156 rtt:0.05/0.007 ato:60 mss:8960 pmtu:9000 rcvmss:1024 advmss:8960 cwnd:10 bytes_sent:30765 bytes_acked:30765 bytes_received:20449 segs_out:473 segs_in:856 data_segs_out:459 data_segs_in:402 send 14.3Gbps lastsnd:24 lastrcv:24 lastack:24 pacing_rate 28.2Gbps delivery_rate 3.98Gbps delivered:460 app_limited busy:228ms rcv_space:56576 rcv_ssthresh:56576 minrtt:0.038
외부에 노출된 프론트 서버나 AWS나 Azure와 같은 public cloud를 함께 사용하는 시스템의 경우 기본값으로 정해진 200ms를 따르는 것이 좋겠지만, 내부적으로 통신하는 서버는 rtt가 매우 짧기 때문에 그에 상응하는 rto_min 값을 설정하여 서비스 품질을 높일 수 있습니다.
5. TCP 재전송과 Application Timeout
시스템에서 TCP 재전송이 발생했을 경우 어플리케이션의 타임아웃 임계치에 따라 어플리케이션 타임아웃이 발생할 수도, 하지 않을 수도 있습니다.
어플리케이션에서 발생할 수 있는 타임아웃에는 크게 Connection T/O과 Read T/O 두 가지가 있습니다.
Connection Timeout은 3 way handshake 과정에서 SYN이나 SYN+ACK 패킷 유실에 의한 timeout입니다. initRTO는 커널에 1초로 하드 코딩되어 있으므로, 2번의 재전송을 보장할 수 있는 3초(1+2)이상의 값이 좋겠습니다.
Read Timeout은 이미 맺어진 세션에서의 데이터 읽기 작업에 대한 timeout입니다. 두 종단 간의 rtt 값과 서버에서 요청을 처리하는게 소요되는 시간을 고려해야 합니다. 가령, 클라이언트 A와 서버 B의 rtt 값이 30ms이고 서버가 이 요청을 처리하는데 200ms가 소요된다고 가정했을 때, 클라이언트와 서버가 통신하기 위해 필요한 최소 시간은 230ms가 됩니다.
여기에 커널의 최소 RTO 값은 200ms를 기준으로 1번의 재전송을 허용한다고 했을 때, 클라이언트가 서버로부터 요청에 대한 응답을 받기까지 소요되는 시간은 430ms가 됩니다.
따라서 Read T/O의 값은 rtt의 값과 요청 처리 시간을 고려하여 설정해야 합니다.
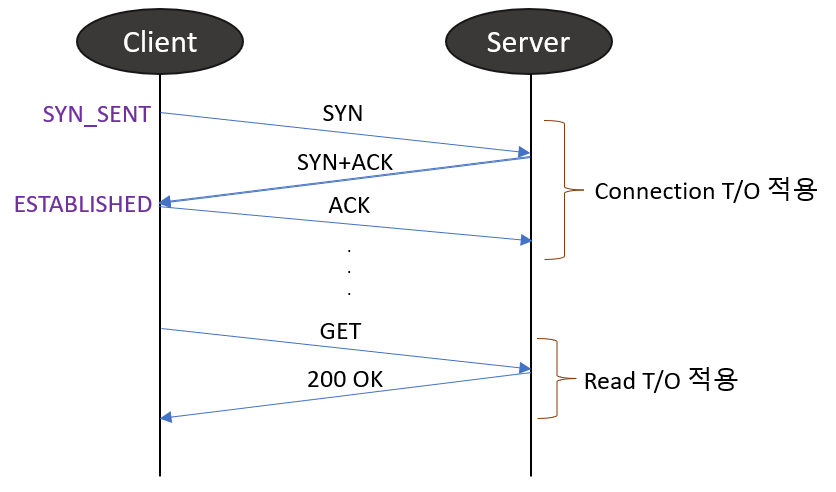
Reference
https://jw910911.tistory.com/35
HTTP 와 TCP의 Keep-Alive
HTTP의 Keep-Alive HTTP 프로토콜의 Keep-Alive는 Http의 Header의 일종입니다.. 이는 HTTP/1.0에서 지원하지 않던 지속 커넥션을 가능하게 하기 위해서 쓰였습니다. 그렇다면 지속 커넥션이 뭔지부터 알아보
jw910911.tistory.com
NGINX를 투명 프록시 (transparent proxy)로 사용하기
해당 포스트에서는 IP Transparency 및 Direct Server Return을 위한 투명 프록시 로 구성하기 위해 NGINX Open Source 및 NGINX Plus를 구성하여 TCP 및 UDP 성능을 향상시킵니다.
nginxstore.com
Installing Haproxy for Kubernetes
If you want to make this scheme more safe you can add haproxy layer between keepalived and kube-apiserver. Just install haproxy package into your system, and add the next configuration into…
kvaps.medium.com
https://datatracker.ietf.org/doc/html/rfc1122
RFC 1122: Requirements for Internet Hosts - Communication Layers
This RFC is an official specification for the Internet community. It incorporates by reference, amends, corrects, and supplements the primary protocol standards documents relating to hosts. [STANDARDS-TRACK]
datatracker.ietf.org
https://alden-kang.tistory.com/20
Connection Timeout과 Read Timeout 살펴보기
오늘은 타임아웃 계의 양대 산맥 Connection Timeout과 Read Timeout에 대해 이야기 해 보려고 합니다. 두 타임아웃의 의미에 대해 살펴보며 적정한 값을 찾는 방법에 대해서 살펴 보겠습니다. Connection Tim
alden-kang.tistory.com
'System Engineering > Linux' 카테고리의 다른 글
| iSCSI Error Handling (0) | 2024.06.16 |
|---|---|
| [커널이야기] 리눅스 I/O 스케쥴러 (1) | 2023.12.12 |
| [커널이야기] TCP handshake와 TIME_WAIT 소켓 (0) | 2023.09.23 |
| [Linux] NTPv4(RFC5905)와 chrony 그리고 timex (0) | 2023.07.21 |
| [커널이야기] 리눅스 더티 페이지와 I/O Throttling (0) | 2023.07.06 |