
시스템을 어떻게 더 공부해야 능력있는 엔지니어가 될 수 있을지 갈피를 알 수 없는 와중에 명령어가 어떻게 동작하는지, 시스템 콜은 어떻게 볼 수 있는지 알 수 있는 시간이었습니다. 좋은 책을 써주신 저자님께 감사드립니다:)
http://www.yes24.com/Product/Goods/44376723
DevOps와 SE를 위한 리눅스 커널 이야기 - YES24
커널은 오랜 세월 기능이 추가되고 개선되어 오면서 완벽하게 이해하기 힘들 정도로 방대해졌다. 하지만 변하지 않는 기본 기능들이 있다. 이런 근간이 되는 기능에 대한 이해를 바탕으로 시스
www.yes24.com
시스템의 부하를 확인할 수 있는 값중 하나인 Load Average가 어떻게 산출되어 어떤 의미를 가지는지 공부한 내용을 정리 해보았습니다.
- Load Average의 정의
먼저, ubuntu 18.04 기준으로 'man proc'를 확인해보면 load average가 다음과 같음을 알 수 있습니다.

load average는 현재 run queue에서 현재 CPU를 사용하여 실행중인 R 상태의 프로세스와 디스크와 네트워크 I/O를 기다리는 D 상태의 프로세스 수를 기준으로 1분, 5분, 15분 통계로 계산됩니다.
- Load Average는 어떻게 산출되는걸까?
시스템의 load average는 uptime 명령어로 간단하게 확인할 수 있습니다.
root@common-server:~$ uptime
08:47:35 up 110 days, 7:23, 2 users, load average: 0.06, 0.04, 0.00
명령어가 실제로 어떤 과정을 거쳐 실행되는지 strace 명령어로 아래와 같이 확인할 수 있습니다.
# strace로 uptime 명령어 시스템 콜 Trace
root@common-server:~# strace -s 65535 -f -t -o uptime_dump uptime
# -s : 출력되는 string의 최댓값 (default 32)
# -t : timestamp
# -f : 멀티 스레드 또는 멀티 프로세스 App을 추적할 때 fork()로 생성된 자식 프로세스까지 추적
...
23826 08:52:21 openat(AT_FDCWD, "/proc/loadavg", O_RDONLY) = 4 # uptime 명령어는 /proc/loadavg의 값을 읽어옵니다.
23826 08:52:21 lseek(4, 0, SEEK_SET) = 0
23826 08:52:21 read(4, "0.04 0.04 0.00 1/816 23826\n", 8191) = 27
23826 08:52:21 fstat(1, {st_mode=S_IFCHR|0600, st_rdev=makedev(136, 0), ...}) = 0
23826 08:52:21 write(1, " 08:52:21 up 110 days, 7:28, 2 users, load average: 0.04, 0.04, 0.00\n", 72) = 72
23826 08:52:21 close(1) = 0
...uptime 명령어는 /proc/loadavg의 값을 읽어와 출력해주는 것을 알 수 있습니다.
root@common-server:~# cat /proc/loadavg
0.02 0.04 0.00 1/812 23869
아쉽게도 시스템에서 /proc/loadavg의 값이 어떻게 계산되는지는 알 수 없기에, ubuntu의 커널 소스를 받아 이해 과정을 확인할 수 있습니다.
// fs/proc/loadavg.c
static int loadavg_proc_show(struct seq_file *m, void *v) {
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
idr_get_cursor(&task_active_pid_ns(current)->idr) - 1);
return 0;
}
// kernel/sched.c
void get_avenrun(unsigned long *loads, unsigned long offset, int shift) {
loads[0] = (avenrun[0] + offset) << shift;
loads[1] = (avenrun[1] + offset) << shift;
loads[2] = (avenrun[2] + offset) << shift;
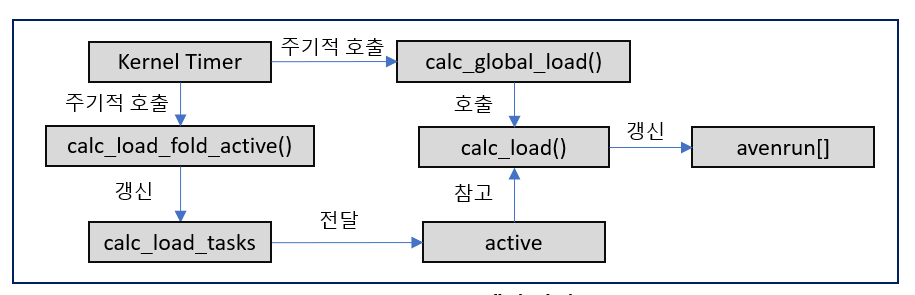
}fs/proc/loadavg.c의 loadavg_proc_show() 함수가 get_avenrun() 함수로 배열 값을 받아 load average를 출력합니다. 그리고 커널 소스에서 'avenrun'을 grep 해보니 kernel/sched/loadavg.c의 calc_load() 함수가 호출되어 avenrun[] 배열에 들어가게 되어있습니다.
$ grep -R avenrun
...
kernel/sched/loadavg.c: avenrun[0] = calc_load(avenrun[0], EXP_1, active);
kernel/sched/loadavg.c: avenrun[1] = calc_load(avenrun[1], EXP_5, active);
kernel/sched/loadavg.c: avenrun[2] = calc_load(avenrun[2], EXP_15, active);
...// kernel/sched/loadavg.c
void calc_global_load(void) {
unsigned long sample_window;
long active, delta;
...
active = atomic_long_read(&calc_load_tasks);
active = active > 0 ? active * FIXED_1 : 0;
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
...
}calc_load() 함수는 loadavg.c의 calc_global_load() 함수 내에서 active 값과 함께 호출됩니다. 그리고 그 active 값은 calc_load_tasks 변수를 읽어온 것입니다. 다시 calc_load_tasks 변수의 의미를 알아보기 위해 grep으로 찾아보니 calc_load_fold_active() 함수에 도달하였습니다.
// kernel/sched/loadavg.c
long calc_load_fold_active(struct rq *this_rq, long adjust) {
long nr_active, delta = 0;
// run queue를 기준으로 R 상태인 프로세스의 개수를 더해줍니다.
nr_active = this_rq->nr_running – adjust;
// adjust = nr_active를 계산하기 위한 스레드 개수(1로 하드코딩)
// D 상태인 프로세스들도 더해줍니다.
nr_active += (int)this_rq->nr_uninterruptible;
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
// nr_active 값이 기존에 계산된 값과 다르면, delta 값을 구해서 calc_load_tasks에 입력합니다.
atomic_long_add(delta, &clac_load_tasks);
}
return delta;
}계산 방법을 찾아가는 과정이 복잡하지만 load average는 커널 타이머에 의해 주기적으로 호출되는 각 함수들이 R 상태와 D 상태의 프로세스의 개수를 세어서 계산됩니다.
load average는 단순히 프로세스 개수만을 계산하기 때문에 CPU 코어의 개수를 포함하지 않습니다. 또한, 발생한 부는 부하가 CPU를 사용하려는 프로세스가 많은 것인지 I/O 병목이 생긴 것인지 알기 어렵습니다.
* /proc/sched_debug 파일로 run queue의 상태와 코어 별 프로세스 정보 등의 스케줄링 현황을 알 수 있습니다.
root@common-server:~$ cat /proc/sched_debug
Sched Debug Version: v0.11, 4.15.0-156-generic #163-Ubuntu
ktime : 31262584096.451380
sched_clk : 31262582575.498740
cpu_clk : 31262582407.838629
jiffies : 12110538321
...
# CPU 코어의 R 상태 프로세스와 D 상태 프로세스 개수
cpu#0, 2399.936 MHz
.nr_running : 0
.load : 0
.nr_switches : 373786471
.nr_load_updates : 176074197
.nr_uninterruptible : 380753
...
# Run Queue의 스케줄링 정보
runnable tasks:
S task PID tree-key switches prio wait-time sum-exec sum-sleep
-----------------------------------------------------------------------------------------------------------
I kworker/0:0H 4 23724.996466 4 100 0.000000 1.731059 0.000000 0 0 /
I mm_percpu_wq 7 20.052567 2 100 0.000000 0.002399 0.000000 0 0 /
S ksoftirqd/0 8 13416111.872742 142098 120 0.000000 1631.896820 0.000000 0 0 /
I rcu_bh 10 26.055174 2 120 0.000000 0.001367 0.000000 0 0 /
S migration/0 11 0.000000 3572 0 0.000000 53.643871 0.000000 0 0 /
S watchdog/0 12 0.000000 7815649 0 0.000000 97173.132783 0.000000 0 0 /
S cpuhp/0 13 24140.028040 18 120 0.000000 1.867886 0.000000 0 0 /
...
- CPU Bound vs I/O Bound
부하를 일으키는 프ㅗㄹ세스는 nr_running으로 표현되는 CPU Bound 프로세스와 nr_uninterruptible로 표현되는 I/O Bound 프로세스 두 가지가 있습니다. 아래 파이썬 스크립트는 실행 시 모두 load average를 상승시키지만 CPU_Bound.py는 단순 연산 작업으로 CPU에 부하를 주고, I/O_Bound.py는 디스크 쓰기 작업으로 I/O에 부하를 줍니다.
* 일반적으로 WAS의 경우 CPU Bound를, DB의 경우 I/O Bound로 볼 수 있습니다.
# CPU_Bound.py
test = 0
while True:
test = test +1# I/O_Bound.py
while True:
f = open("/io_test.txt", 'w')
f.write("TEST")
f.close()
CPU 부하가 심하다는 것은 각 프로세스의 CPU 경합이 치열하는 것을 의미합니다. 그리고 이것은 AWS나 Azure와 같은 Public Cloud로 Migration 하거나 서버 증설 또는 Load Balancing만으로도 해결이 가능합니다. 반면, 디스크의 Read/Write 작업은 CPU 처리 속도에 비해 현저히 느리므로 단순한 서버 증설로는 병목 해결이 어렵습니다.
I/O 부하를 해소하기 위해서는 메모리를 증설하여 캐시 적중률을 높이거나 데이터를 압축하는 절차를 도입하여 I/O 부하의 일부를 CPU 부하로 전이하는 방법 등이 있습니다. DB의 경우 샤딩이나 파티셔닝을 통해 데이터를 분산하여 부하를 줄 일 수 있습니다.
* vmstat 명령어로 시스템에 어떤 종류의 부하가 많은지 확인할 수 있습니다.
root@common-server:~$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 315493024 1195712 67822728 0 0 0 2 0 0 0 0 100 0 0
0 0 0 315493216 1195712 67822800 0 0 0 24 1843 3794 0 0 100 0 0
0 0 0 315493120 1195712 67822800 0 0 0 32 2103 4486 0 0 100 0 0
0 0 0 315492992 1195712 67822800 0 0 0 48 2230 5436 0 0 100 0 0
0 0 0 315493120 1195712 67822800 0 0 0 36 2051 4879 0 0 100 0 0
0 0 0 315493376 1195712 67822800 0 0 0 68 1960 4392 0 0 100 0 0
0 0 0 315493280 1195712 67822800 0 0 0 8 2280 4914 0 0 100 0 0
2 0 0 315493408 1195712 67822800 0 0 0 0 1813 4015 0 0 100 0 0
부하 (컴퓨터) - 해시넷
부하(負荷, load)란 시스템에서 원하는 어떤 효과를 얻기 위해 취하는 행동에 필요한 동작이나 자원을 말한다. 예를 들어, 운영체계에서 프로세스들을 스케줄링(scheduling)함으로써 컴퓨터 자원의
wiki.hash.kr
'System Engineering > Linux' 카테고리의 다른 글
| [커널이야기] 리눅스 더티 페이지와 I/O Throttling (0) | 2023.07.06 |
|---|---|
| [커널이야기] 리눅스 메모리 1 - 메모리를 확인하는 방법과 slab/swap 메모리 (2) | 2023.06.15 |
| 폐쇄망 환경에서 휴대폰 테더링으로 yum/apt 사용하기 (0) | 2023.04.20 |
| [커널이야기] Linux top 명령어와 프로세스 (0) | 2023.04.13 |
| [커널이야기] Linux 시스템의 구성 정보 확인하기 - BIOS / CPU / NUMA / NIC / DISK (0) | 2023.04.11 |