Node Problem Detector and Draino
1. 개요
Kubernetes에서는 kube-node-lease를 통해 Host(Worker)의 단순한 Health Check만 할 수 있으며, 아래처럼 다양한 문제를 감지할 수 없습니다.
- CPU, Memory, Disk 등의 하드웨어 문제
- Kernel과 File System의 문제
- Docker 또는 Container Runtime 문제
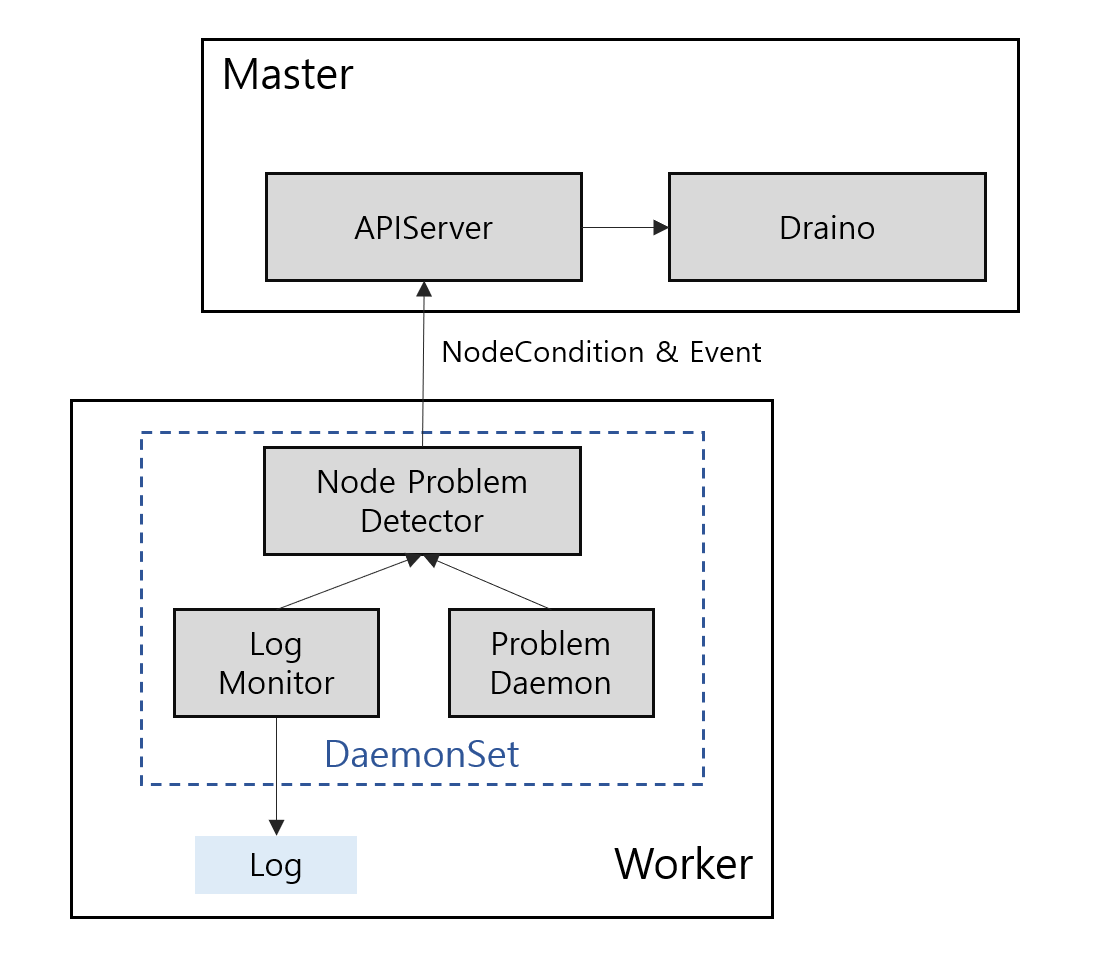
2. Node Problem Detector
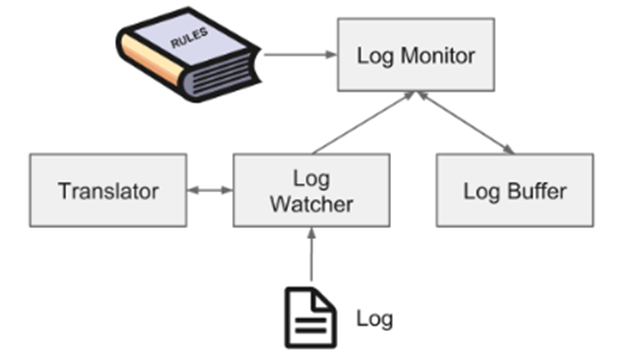
- Problem Deamon : Node-Problem-Detector의 서브 데몬으로 아래 4가지 타입이 있으며, 타겟에 따라 로그나 데몬을 감시하고 설정된 predefined rule의 정의에 따라 kube-apiserver로 보고하여 Remedy System(Draino)에서 node cordon과 같은 조치를 시도하거나 'kubectl get events'로 발생한 문제를 조회할 수 있습니다.
- SystemLogMmonitor - kern.log, kmsg, journald
SystemStatsMonitor- CustomPluginMonitor - NTP
- HealthChecker - kubelet, Container Runtime
3. Draino
Draino는 node의 label과 node-problem-detector에서 감지된 NodeCondition을 기준으로 node에서 cordon이나 drain이 동작하게 하여 Pod가 스케줄링되는 것을 방지합니다. 나아가서 Cluster Autoscaler로 K8s cluster에서 문제가 되는 node를 제거할 수 도 있습니다.
Reference
https://github.com/kubernetes/node-problem-detector
GitHub - kubernetes/node-problem-detector: This is a place for various problem detectors running on the Kubernetes nodes.
This is a place for various problem detectors running on the Kubernetes nodes. - GitHub - kubernetes/node-problem-detector: This is a place for various problem detectors running on the Kubernetes n...
github.com
https://github.com/planetlabs/draino
GitHub - planetlabs/draino: Automatically cordon and drain Kubernetes nodes based on node conditions
Automatically cordon and drain Kubernetes nodes based on node conditions - GitHub - planetlabs/draino: Automatically cordon and drain Kubernetes nodes based on node conditions
github.com